我们新版app上线了,由于这次是一个大的改版,所以希望所有用户都升级到新版本,所以,一方面我们会在后台做一些限制来强制升级,另一方面我们也会推送介绍新版的消息给用户,也顺便提醒一些不活跃的用户。当然,做这些事都是要尽量保证用户体验,所以,对于那些已经升级到新版本的用户,就不应该再收到我们推送的消息了。
因此,根据一些策略过滤之后,大概还有210万的用户需要推送消息,这么大的量没法手动操作,只能用程序来搞定了。很久以前我对这些数量其实并没有多大感知,但是最近接触的多了也就知道,数量大了之后就会有一些问题,比如服务的稳定性就需要考虑进去了,推送10个人可能一秒钟都不到,但是这百万量级,可能就需要几个小时了,这种推送时间太长肯定也是不能接受的。(比如昨天,我给一些用户补标,数量大概在500万左右,因为我考虑到不是很急,所以就只用了一个进程来跑,结果整整跑了24小时才结束,虽然是不急,但是这个时间也是太长了,还是自己的考虑欠缺,因为在运行之前并没有通过计算去预估它的时间)
这次首先就考虑到了redis的读写压力,网络请求的速率等等情况,然后是准备在这边的调用方来限速,避免对后端的服务造成压力来保证服务的可靠,因为当时做这个后端服务接口的时候,主要就是给运营人员推送消息用的,而运营的消息,一天最多一条或者很多天才一条,因为消息多了会让用户反感。所以也就没考虑到会有这种场景,段时间内几百万的量,因此也就没有做压力测试,不知道上限在哪里,现在也就只能根据经验猜测,然后在调用端限制调用频率。不过,我先用了10个测试帐号,来具体看看,推送每个用户大概需要多少时间,然后发现每个用户的耗时在72~75毫秒的样子,这样1秒钟可以推送14个用户,1分钟可以到840~900个用户的样子,我用10个并发来进行,也就可以达到1分钟推送8400~9000个用户,所以200万的用户,大概需要220~240分钟,差不多4个小时。这个并发量对后端服务来说基本是可以的,虽然时间还是有点长,但也只能先这样了。
同样的我先启动了2个进程,看看服务是否稳定,在看上去没有问题,各个监控也都正常,然后就放开了10个进程,当然,请求量自然一下就上来了,同样的先上图: 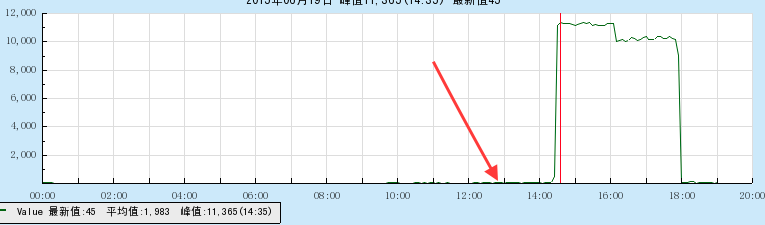 图中大概可以看到10个进程的请求量每分钟大概在11000~12000的样子,比上面预计的要快一些,同时也可以看到图里面,平时的请求量都只有几十的样子,现在突然升到1万以上,所以那些几十的曲线基本不可见了,那我把箭头处的曲线图放大来瞧瞧:
图中大概可以看到10个进程的请求量每分钟大概在11000~12000的样子,比上面预计的要快一些,同时也可以看到图里面,平时的请求量都只有几十的样子,现在突然升到1万以上,所以那些几十的曲线基本不可见了,那我把箭头处的曲线图放大来瞧瞧: 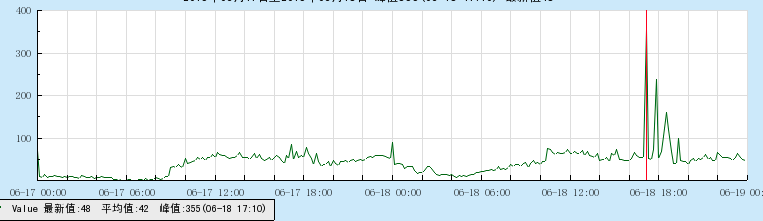
数量上来之后,多少都会影响稳定性的,因为平时都是0错误的,而现在,出现了部分错误,不过错率在可接受的范围,最后的结果来看,200万的数量,错误数在200+个,大概是万分之1.2的错误率,并没有多大影响。总共耗时是3.5小时,不过我们的服务还是很有优化的空间的,正好最近也在慢慢的重构各个模块的代码(重构代码这种事真的需要自下而上的推动,同时也要老大同意),也算是很能增长经验值的了。
2015.06.19 21:17